
請求書や帳票をデータ化するOCR(光学的文字認識)は、バックオフィス自動化の「入口」となる技術です。
従来のOCRは文字の形を読み取るだけで、事前のテンプレート設定や手作業での修正など、二度手間が発生しがちでした。
しかし現在、AI技術、特に画像を理解するAI(VLM)の登場により、OCRは「文字を読む」だけでなく「意味を理解し、データとして整える」ことまでを一括で行う時代へと進化しています。本記事では、AI-OCRの仕組みから最新ツール、導入時の注意点までを基礎から解説します。
OCRとは何か ― 紙をデータに変える自動化の入口
OCR(Optical Character Recognition:光学的文字認識)とは、紙の書類やPDF、画像の中に含まれる文字を、コンピュータが扱えるテキストデータに変換する技術です。スキャナが書類を「絵」として写し取るのに対し、OCRはその絵の中にある文字を「読んで」データ化します。
バックオフィス業務において、OCRは紙やPDFで届く請求書や帳票をデータ化する最初のステップとなります。読み取ったデータをRPA(定型作業を自動化するソフトウェアロボット)に渡し、会計システムへ自動入力させることで、大幅な業務効率化が可能です。
実際の現場では、月に2,000件の帳票入力にかかる時間を272時間から117時間へと約6割削減した事例や、請求書の読み取りから仕訳までの作業を月30時間から3時間へと9割削減した報告もあります。また、自治体におけるアンケート集計業務を72時間から12時間に短縮したケースも存在します。
従来型OCRが抱えていた「精度の壁」
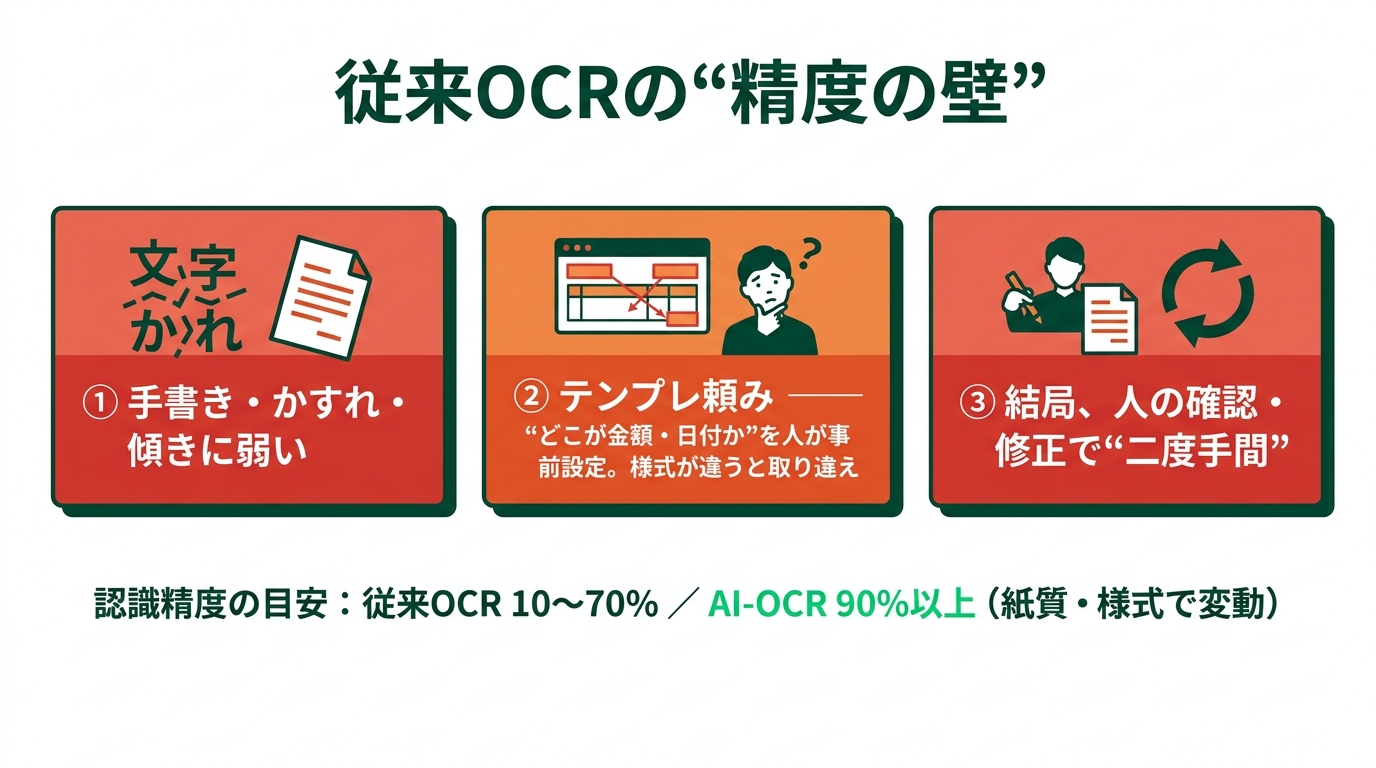
自動化の強力な武器となるOCRですが、従来型の技術には実務上の大きな壁が3つありました。
1. 手書きやかすれ、傾きに弱い
きれいな印字の読み取りは得意ですが、乱筆の手書き文字やかすれたコピーなどは誤認識しやすくなります。
2. テンプレートへの依存
「この位置にある数字が金額」「ここが日付」といった読み取り位置を、人が事前に設定する必要があります。取引先ごとにレイアウトが異なる請求書が届くたびに、新しいテンプレートを作成しなければならず、膨大な手間がかかります。
3. 人の手による修正(二度手間)
非定型の帳票や表の読み取りがうまくいかず、結局は人が目視で確認し、手作業で修正する二度手間が発生します。従来型OCRの認識精度は一般に10〜70%程度と言われており、手入力と手間が変わらない事態に陥りがちでした。
AI-OCRへの進化 ― AIが文脈から項目を判断
こうした従来型の課題を解決したのが、機械学習を組み合わせた「AI-OCR」です。一般的に90%以上の認識精度を持つとされています(精度は紙質や様式により変動します)。
最大の違いは、AIが前後のつながりや文脈から「これが合計金額である」「これが日付である」と自ら判断する点です。これにより、取引先ごとに異なる様式であっても、事前の位置設定がほぼ不要になります。
また、手書き文字の読み取り精度も格段に向上しており、使えば使うほど学習して精度が上がるという特徴を持っています。ただし、どのような書類を読み込ませて学習させたかが結果に影響するため、自社の実際の書類を用いてチューニングを行うことが重要です。
VLMがもたらす革新 ― 読んで理解し、一発でデータ化
ここ1〜2年で、OCRの技術はさらに大きな飛躍を遂げました。その鍵となるのが「VLM(ビジョン・ランゲージ・モデル)」です。VLMとは、画像も理解できる大規模言語モデルのことで、GPT-4o、Claude、Geminiなどが該当します。
従来のAI-OCRでは、まず文字を読み取り、次に別の仕組みで必要な項目を切り出すという二段構えの処理が必要でした。しかしVLMを用いれば、請求書の画像を直接渡し、「取引先・金額・日付をJSON形式で抽出して」と自然な言葉で指示するだけで処理が完結します。JSONとは、コンピュータが扱いやすいように項目と値がセットになったデータ形式です。
VLMは、文字を「読む」、意味を「理解する」、そして指定された形式に「構造化する」工程を一度に行います。Mistral AIが提供する「Mistral OCR 4」などの最新モデルでは、文字の位置情報や読み取りの「自信度」まで付与して構造化することが可能です。日本語に特化したものとしては、「Chandra」や「HunyuanOCR」、国産オープンソースの「YomiToku」などがあり、縦書きや表の読み取りに優れています。
調査会社Gartnerによると、企業の文書処理において、AIに意味を理解させる方式を検討している割合は、2年前の23%から67%へと急増しています。
代表的なツールと活用事例
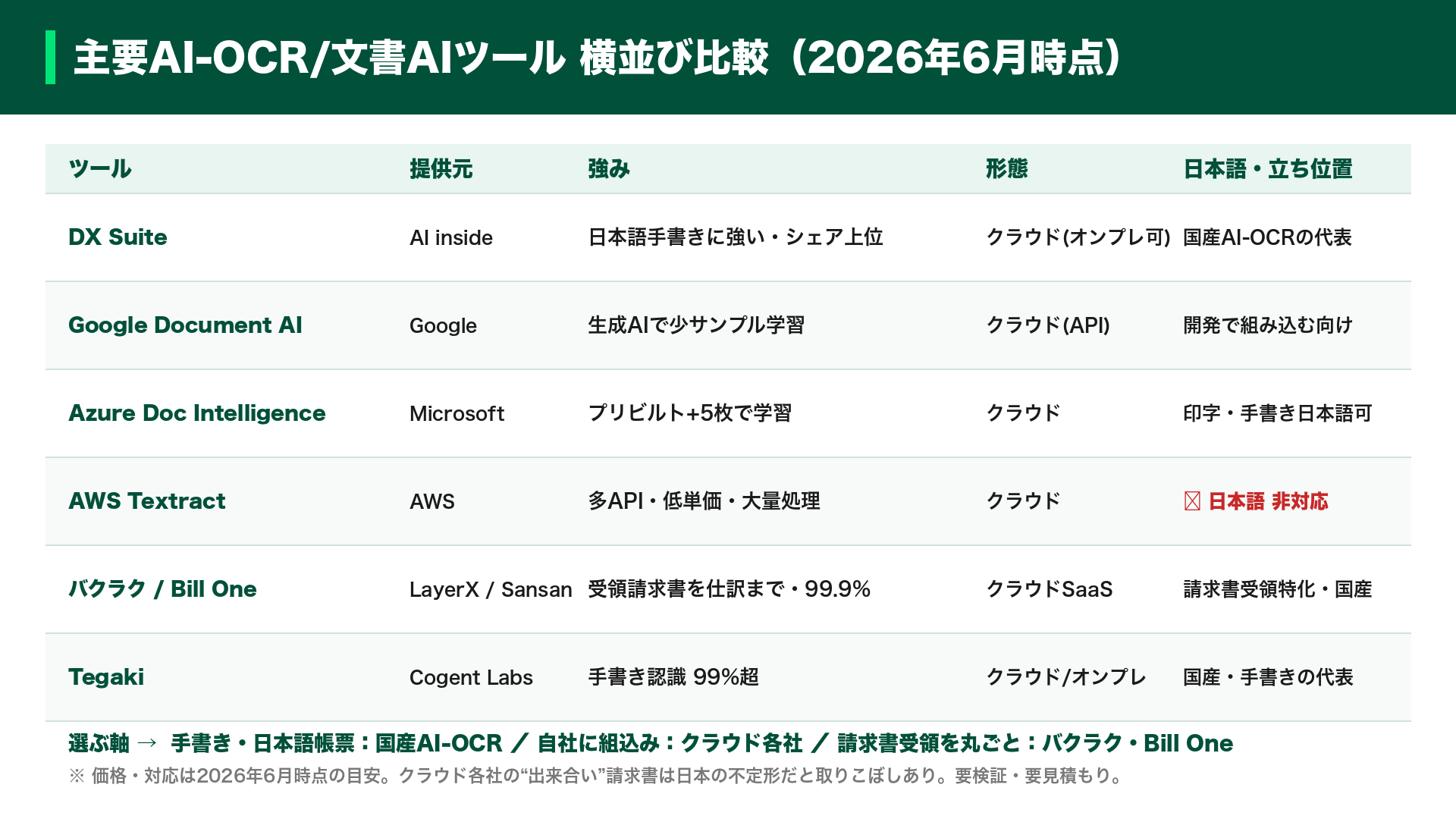
実務で活用できる代表的なツールは、用途に応じて分かれます。日本語の手書き帳票に強いのが、AI insideの「DX Suite」です。国内トップクラスのシェアを持ち、自治体や金融機関で広く導入されています。
自社システムに組み込む場合は、Googleの「Document AI」やMicrosoftの「Azure Document Intelligence」が有力です。なお、AWSの「Textract」は強力ですが日本語に非対応であるため注意が必要です。
請求書の受け取りから会計連携までを自動化したい場合は、LayerXの「バクラク」、Sansanの「Bill One」、「invox」などの専用サービスが適しています。バクラクの事例では、請求書関連業務を6割超削減し、「AI明細仕訳」機能で明細入力の9割以上を自動化しています。手書き書類に特化するなら、Cogent Labsの「Tegaki」があります。
実際の導入効果として、京葉銀行ではDX SuiteとRPA(WinActor)の組み合わせにより、82業務で合計2万6千時間を削減しました。ある医療法人では手書き書類と電子カルテの処理で年間約1,800時間、自治体では東京都港区が年間2,000時間、豊中市が5,000時間規模の業務削減に成功しています。
導入前に知っておくべき4つの落とし穴
AI-OCRやVLMは強力ですが、運用にあたっては以下の4点に注意が必要です。
1. 精度は100%ではない
認識精度が99%であっても、残り1%の誤りを防ぐために人の目による最終確認は必須です。特にお金や契約に関わる重要書類では、確認プロセスを省くことはできません。
2. ハルシネーション(もっともらしい誤り)
VLM特有の課題として、かすれて読めない文字を、文脈に合わせてAIが勝手に推測し、存在しない言葉を作り出してしまう「ハルシネーション」があります。日本語の検証では、「なめたけ」を「なめたいこと」と誤読した事例も報告されています。AIが提示する自信度スコアを確認し、人が最終確認する運用が求められます。
3. 機密情報の取り扱い
クラウド型のOCRを利用する場合、読み取る書類の画像データが外部に出ることになります。マイナンバーなどの機密書類を処理する場合は、オンプレミス(自社運用型)や手元のローカル環境で処理できるツールを選ぶ必要があります。
4. コストと用途の使い分け
VLMは高度な処理が可能ですが、従来型OCRと比較して処理速度が遅く、コストが高くなる場合があります。毎月同じ様式の書類を大量に処理するなら高速な従来型、様式がバラバラな非定型書類ならAI-OCRやVLMといったように、用途に応じた使い分けが重要です。
まとめ
- OCRは紙をデータに変える自動化の入口。AI-OCRの登場により、事前のテンプレート設定なしにAIが文脈から項目を判断できるようになりました。
- VLM(画像を理解するAI)の活用で、書類を「読む」「理解する」「データに構造化する」工程が一度に完了し、非定型書類の処理能力が飛躍的に向上しています。
- 精度は100%ではないため、重要書類の目視確認やハルシネーション対策は必須です。また、機密情報の取り扱いや用途に応じたツールの使い分けが成功の鍵となります。
バックオフィスのBPO・AI内製化のご相談
「どのツールを入れるべきか」の棚卸し・診断から、現場で本当に使われる運用設計まで。経理・労務・採用・営業事務のBPO、AIガバナンス整備までご支援します。
資料を見る